NextcloudにLocalAIを導入してみる(CPU)
Geminiちゃんの1日の制限が厳しくなったので完全ローカルのLocalAIをテストした時のメモです。
正直な話ですがこれは無茶です。
ローカルサーバーならGPU買えば問題ないですがクラウドでやるならConoHa VPSでNVIDIA L4サーバーを借りて月最大39,930円なり!
Xserverは月最大88,000円なり!
NextcloudにAIを導入するメリットはあるかわかりませんがクラウドで安く済ませるならCloudflare TunnelでローカルからGPUを引っ張る方がいいかもです。
2GB VPSでも1,2bパラメータなら案外早かったですが生成したものは終わっています。
あと注意として既にgeminiとか登録していると1日程度、urlやipが残ってテストができなかったです。
色々キャッシュは消してみたけどどこにキャッシュしてるか不明で消えてくれなかったので1日放置してたら勝手に消えてました。
Nginxな気はしますがlocalhost、ドメイン、固定IPを指定していない場合は注意。
今回のテスト環境はConoHaの3コア 2GBのUbuntu 24です。
Nextcloud自体はOracleのVPSで構築しています。
VPSの最低ラインは2GBです。
※もしかしたらスクリプトを作成する必要があるかもしれないのでもし応答がないとかあればNextcloudにAI統合をする(Gemini)を確認してください。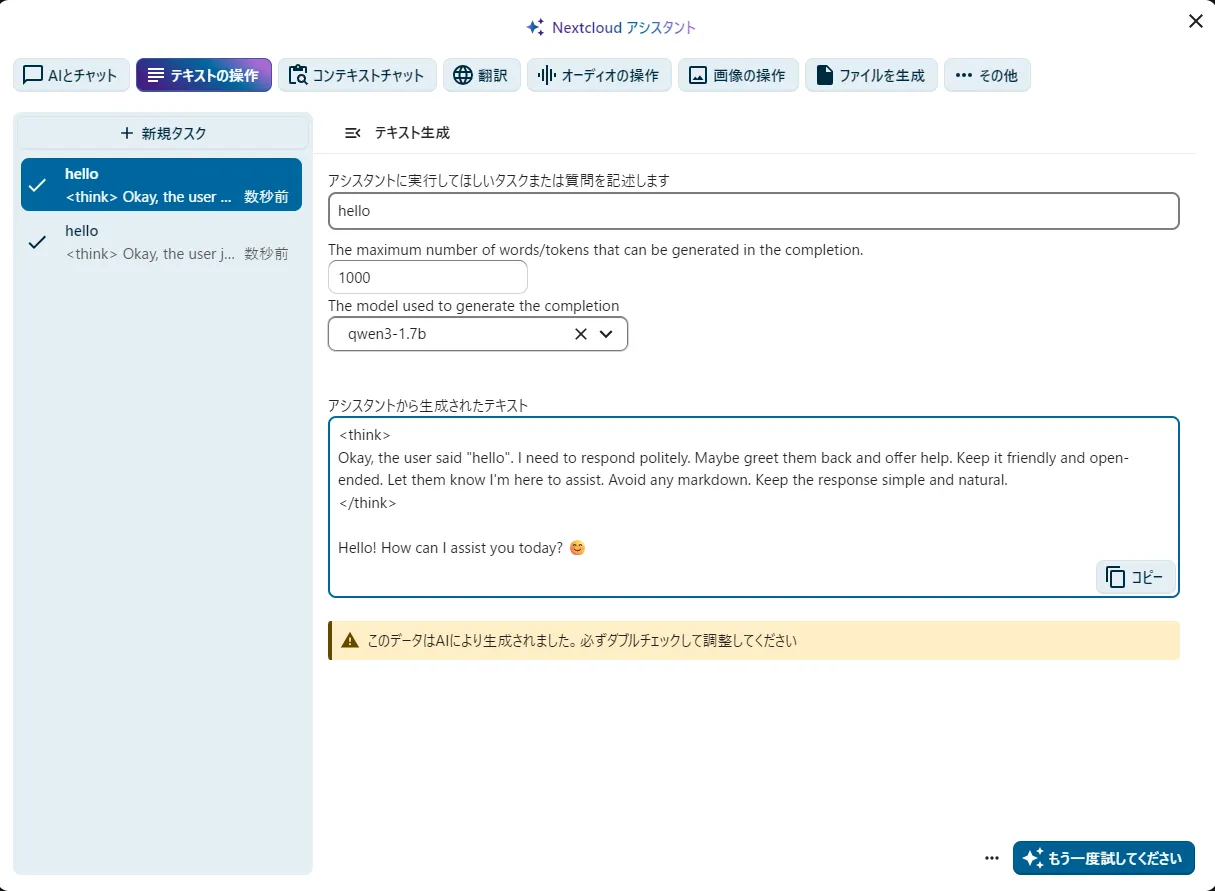
更新しておく
更新を念のためかけておきます。(updateだけでいいです)
sudo apt -y update
sudo apt -y upgrade
Dockerをインストールする
パッケージの更新をする
sudo apt -y install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release
Docker公式のGPG鍵を追加する
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | \
sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
最新の安定版(stable)を取得する。
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
インストールする
sudo apt -y update
sudo apt -y install docker-ce docker-ce-cli containerd.io
Swap領域を作成する(必要なら)
3コア 2GBという格安のVPSプランでのテストの為,Swap領域を念のため
もともとVPSなりが4GBとかあるなら1,2bのモデルであればいらないですしスワップ領域にモデルが溢れた時点でtoken速度が終わります。
4GBのスワップファイルを作成
sudo fallocate -l 4G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
再起動しても有効になるように設定
sudo echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
LocalAIの構築 (Docker)
今回は/opt/localaiで作業します。
sudo mkdir -p /opt/localai/models
cd /opt/localai
モデルファイルをダウンロードする
※GPU版の方にはコマンドでダウンロードする方法を書きました
モデルはggufの1,2bあたりを用意してください。
qwen3 の0.6,1.7bあたりがまだましでした。
LM Studioで適当にダウンロードして使えそうなモデルを転送した方がいいかもしれないです。
Qwen3-0.6B-Q8_0.gguf の量子化モデル(Q8_K_M)をダウンロードする場合。(Q4の方が早いので必要ならhuggingfaceで探してください。)
1B以上がほしい?無茶ですね
sudo wget -O models/Qwen3-0.6B-Q8_0.gguf https://huggingface.co/Qwen/Qwen3-0.6B-GGUF/resolve/main/Qwen3-0.6B-Q8_0.gguf?download=true
docker-compose.yml の作成
sudo vi docker-compose.yml
以下を貼り付ける(APIキーなどは変更してください)
services:
local-ai:
image: localai/localai:latest
container_name: local-ai
restart: always
ports:
- "8080:8080"
environment:
- MODELS_PATH=/build/models
- THREADS=3 # VPSのコア数に合わせる
- CONTEXT_SIZE=2048 # メモリ節約のためコンテキスト長を制限(重要)
- API_KEY=momijiina #好きなキーに変更してください。Nextcloud等で使うキーです。
volumes:
- ./models:/build/models
command: ["/usr/bin/local-ai"]
起動する
sudo docker compose up -d
バックエンドをインストールする
ブラウザ経由なら簡単ですがコマンドのみだと面倒ですね。
古いバージョンは入っていたので導入されているものだと勘違いしてましたね。
バックエンド一覧を取得する
インストール可能なバックエンドを表示できます。
AIモデルも似た感じで表示とインストール可能でした。
curl -s http://localhost:8080/api/backends \
-H "Authorization: Bearer momijiina" | sed -n '1,200p'
llama-cppをインストール
momijiinaはAPIキーですlocalhostとポートも自由に変更してください。
curl -s -X POST "http://localhost:8080/api/backends/install/localai@llama-cpp" \
-H "Authorization: Bearer momijiina"
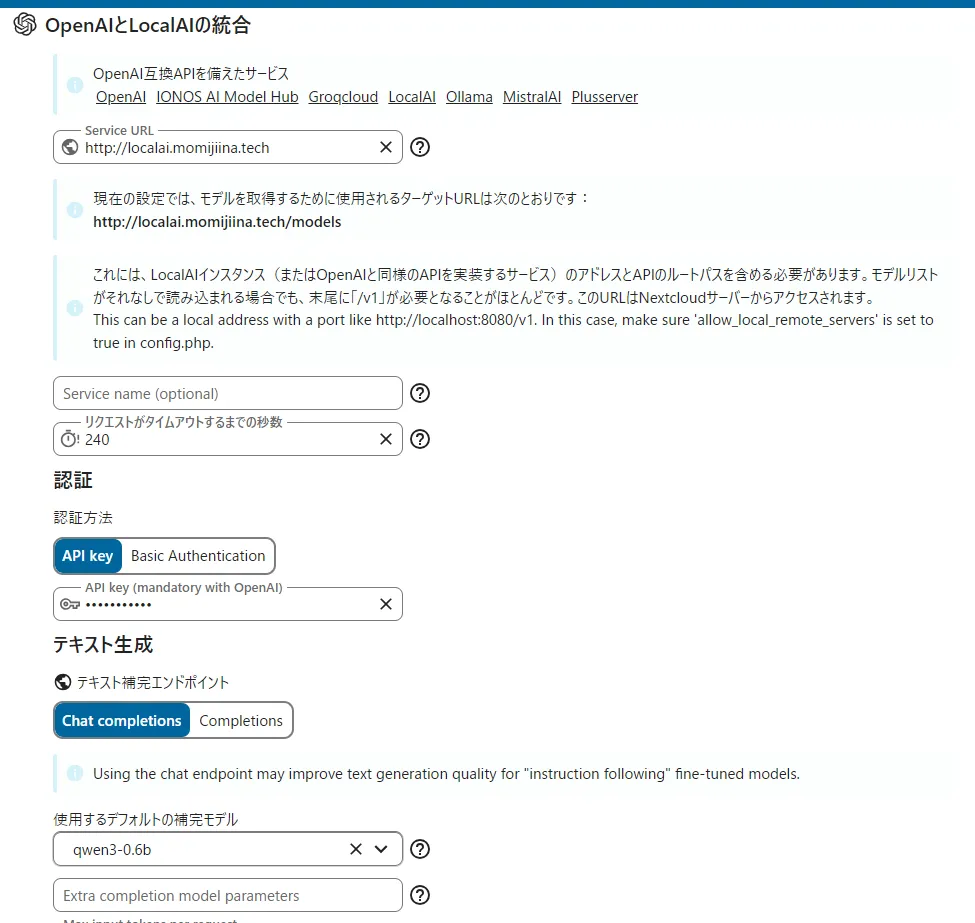
Nextcloudで設定する(サーバーが同じ場合)
Nextcloudのアシスタント設定を開きます。
Service URL: http://localhost:8080
APIキー:先ほどdocker-compose.ymlで設定したキーを使用
momijiina
テキスト生成などで先ほどダウンロードしたモデル名をリストから指定
モデル名: Qwen3-0.6B-Q8_0.gguf
Nextcloudで設定する(Nginx経由)(メリットあり)
スペック的にサーバーを分ける場合やドメインを割り当てる場合です。
Nginxは最新版を入れている前提とします(1.28が2026年1月時点では最新)
confファイルを以下のように設定する(例です)
443での設定も似たようなものなので今回は省略
server {
listen 80;
server_name ドメインやIPを指定;
location / {
proxy_pass http://localhost:8080;
proxy_read_timeout 600s;
proxy_connect_timeout 600s;
proxy_send_timeout 600s;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_cache off;
proxy_http_version 1.1;
chunked_transfer_encoding on;
}
}
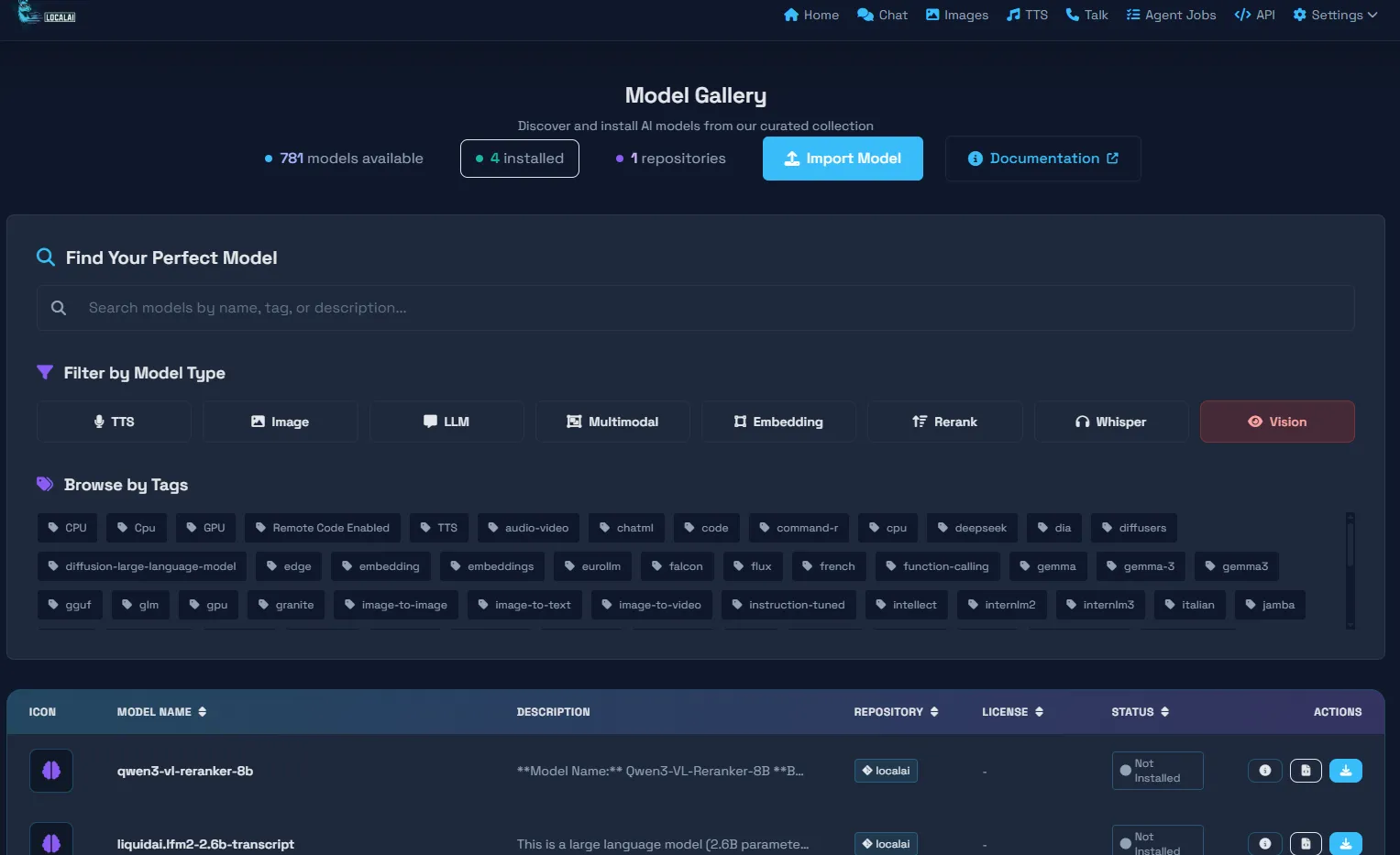
Nextcloudで設定する
メリット
Nginx等を経由してブラウザで開くと以下のような管理パネルでモデルダウンロードしたりチャットしたりできます。
APIキーを設定していないと危険なので注意

動作テストする
VPS2GBでも5-10秒で以下のような結果が得られます。
Q4で0.6bで30token/s,Q8だと0.6bで30token/sでした。
root@vm-7426b837-ca:/opt/localai# curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer momijiina" \
-d '{
"model": "Qwen3-0.6B-Q8_0.gguf",
"messages": [{"role": "user", "content": "こんにちは、面白ことをいってみて"}]
}'
{"created":1768537754,"object":"chat.completion","id":"8ecb8eef-aa29-4e90-8f13-355f09adebeb","model":"Qwen3-0.6B-Q8_0.gguf","choices":[{"index":0,"finish_reason":"stop","message":{"role":"assistant","content":"\u003cthink\u003e\nOkay, the user said \"こんにちは、面白ことをいってみて\" which translates to \"Hello, have you had fun?\" in English. I need to respond appropriately. Let me think about how to reply. Since they're greeting me, the best way is to acknowledge their greeting and show interest. Maybe mention something about being here to help or be fun.\n\nI should make sure the response is friendly and open-ended. Let me check if there's a specific context they might be in, but since it's a general greeting, keep it simple. Avoid any technical terms. Alright, something like \"Hello! I'm here to help, and I hope you had fun!\" sounds good. That covers the greeting and offers assistance.\n\u003c/think\u003e\n\nこんにちは!面白ことをいってみてたらいいな、って感じですね。笑顔でいるってことありますから、いつでもお手伝いできますよ!😊"}}],"usage":{"prompt_tokens":15,"completion_tokens":186,"total_tokens":201}}
APIキーありの場合
momijiinaは設定したAPIキーです。
localhostは必要があればローカルIPやドメインに変更
ポートも必要があれば削除したり変えたりしてください
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer momijiina" \
-d '{
"model": "Qwen3-0.6B-Q8_0.gguf",
"messages": [{"role": "user", "content": "こんにちは、面白ことをいってみて"}]
}'
APIキーを設定していない場合
localhostは必要があればローカルIPやドメインに変更
ポートも必要があれば削除したり変えたりしてください
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-0.6B-Q8_0.gguf",
"messages": [
{"role": "user", "content": "こんにちは、面白ことをいってみて"}
],
"temperature": 0.7
}'
スクリプトの作成
スクリプトはやっぱり必要だったのでgemini版から移植しました。
Screenコマンドで動かしててもいいですかそれだと再起動した際に終了してしまうのでサービスとスクリプトを作成します。
スクリプトを作成
sudo mkdir /opt/nextcloud-ai-worker
sudo vi /opt/nextcloud-ai-worker/taskprocessing.sh
以下をコピー(パスは編集してください) 必要があれば他も編集してください
#!/bin/sh
echo "Starting Nextcloud AI Worker $1"
cd /var/www/nextcloud
/usr/bin/php occ background-job:worker 'OC\TaskProcessing\SynchronousBackgroundJob'
権限変更
sudo chown -R www-data:www-data /opt/nextcloud-ai-worker
サービスの作成
自動起動と常駐化をします。
sudo vi /etc/systemd/system/nextcloud-ai-worker@.service
以下をはりつけてください。
[Unit]
Description=Nextcloud AI worker %i
After=network.target
[Service]
ExecStart=bash /opt/nextcloud-ai-worker/taskprocessing.sh %i
Restart=always
StartLimitInterval=60
StartLimitBurst=10
User=www-data
[Install]
WantedBy=multi-user.target
起動とステータス確認
sudo systemctl daemon-reload
sudo systemctl enable nextcloud-ai-worker@1.service
sudo systemctl start nextcloud-ai-worker@1.service
systemctl status nextcloud-ai-worker@1.service